MTR is a great tool to understand if there is a routing issue. There are many times, customer says the website/web server is slow or not being able to access the network etc. After some basic checks, if no solution is concluded, it is important to get a MTR report from the client. As most of the users use Windows, it is common to use WinMTR.
To run WINMTR, you need to first download it from here:
https://sourceforge.net/projects/winmtr/
or here
https://winmtr.en.uptodown.com/windows
Once the app is downloaded, double clicking it will open it. WinMTR is a portable executable binary. It doesn’t require installation.
Once opened, you can enter the ‘domain name’ that is having trouble in the ‘Host’ section and press start.
Once you start, it will start reaching the domain you entered and hit each of the node it passes for routing, with giving the amount of drops each node is hitting
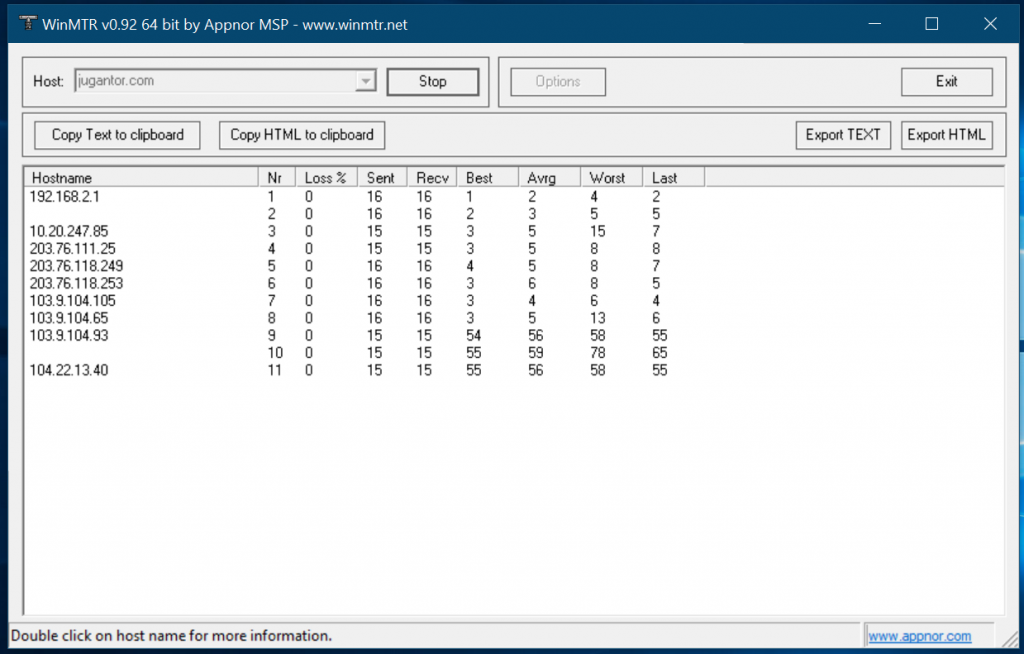
If you are seeing drops of anything above 2-5%, that node is problematic. If the node is dropping a lot, but the next node isn’t dropping enough, then the node is set to transparently hiding the packet responses for security, then that node is not problematic. So if your packet isn’t reaching the destination and it is dropping somehwere or looping in a node, that means, the problem is within that node. Now you can locate the node and see where does it belong. If it belongs to within your territory, then the issue is within your ISP or IIG. But if it is outside your territory but at the end of the tail, then the issue is with the Host.
In most case, we ask for running the MTR for 5 minutes and then export to TEXT and send it over for us to analyse to customers. You can export the report by stopping the MTR and clicking ‘Export TEXT’ available in the winMTR window.