For past one month, Openlitespeed has been my favorite piece of web server. Litespeed has always outperformed all the other webservers including Nginx as well in any of my production environment. But I have recently switched to using OLS which is a Opensource version of Litespeed with some limited features. I get LS kind of performance along with no worry for paying. How better could it be?
OLS comes with some weird problem. As OLS is less used, finding a solution for such cases could be difficult. I faced a very similar kind of issue yesterday.
I added a OLS based server to my HAProxy cluster, but the HAProxy can not find the OLS server working. When I try to access the web app hosted under OLS server using local IP masking, I see the website without a problem. That means, OLS is interpreting the Domain with IP relation well. But failing to respond when Haproxy is requesting through IP address.
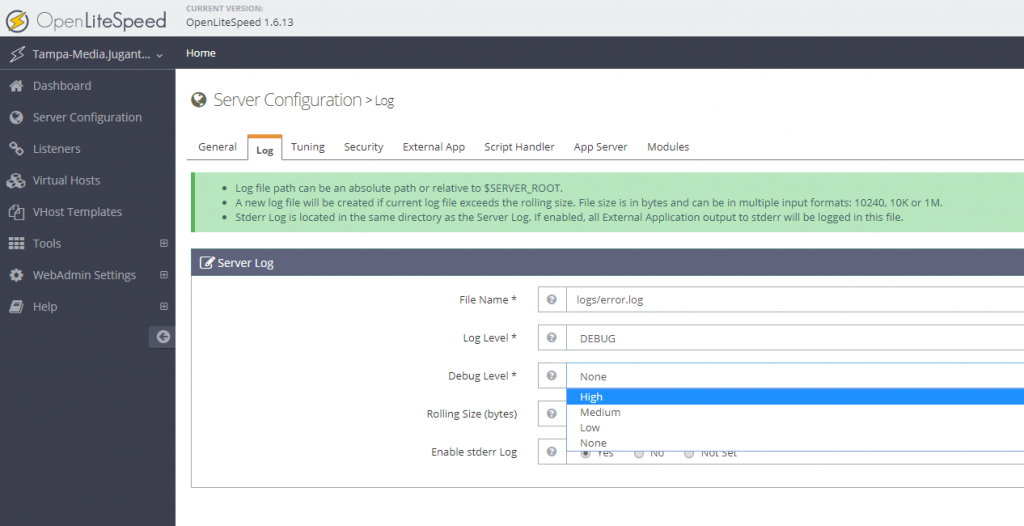
The problem is, OLS is not configured to respond to ‘default’ requests on ‘127.0.0.1’, ‘localhost’ or the server’s main IP. To find out this, I enabled ‘High’ Debug mode of OLS. To do this, first visit the OLS Webadmin Console, it can be accessed with https://IP:7080
After login, go to Server Configuration >> Log >> Edit Server Log >> Set ‘Debug Level’ to High and Save
Once saving is done, you may gracefully restart the OLS
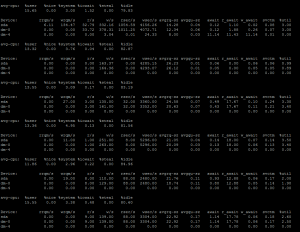
Once this is done, you may now monitor the error.log file located usually under /usr/local/lsws/logs. Now tail the output of error.log while processing requests with Haproxy:
tail -f /usr/local/lsws/logs/error.log
You can see, OLS has returned 404 error for the localhost/ request. That means, Haproxy is requesting the IP with a header ‘localhost/’, and the server should return something with code 200 to make sure the server is in business.
What we need to do, is to make OLS respond to request for basic IP and localhost to 200 with the main site instead of ‘404’ error. To do this, we need to go to Webconsole of OLS again >> Listeners
You will see you have two Listeners, one for Default/Non HTTP and the HTTPS/SSL. In my case, I was using only HAProxy to Origin with no SSL, means 80. I selected the Default.

In the Listener List, you can find your Virtualhost, click on the ‘Edit’ of your Virtualhost

Now, you can map the virtualhost. You will see your primary domain as the ‘Virtual Host’, which can’t be changed here. But what you can do is to map this virtualhost to several domains. The trick is to add your server’s IP and the localhost in the ‘domains’ list with comma seperation as following:

Once this is saved, restart your OLS and now your HAProxy should be able to read requests and starting forwarding requests to your OLS server.