I have a SQL query, how can I create a CSV file from the SQL Query?
Solution
I had a customer looking for such an option. This can be easily achieved using ‘into outfile’ attribute of MySQL. Let me provide an example query like the following:
select * from wp_woocommerce_orders left join wp_posts on wp_posts.id = wp_woocommerce_orders.order_id into outfile '/var/lib/mysql/orders_list.csv' FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
The above query is joining the order table of woocommerce with the WordPress posts table, and putting the output file in /var/lib/mysql/orders_list.csv file, in which each field is being terminated by a comma (aka comma separated file) and after each row, it is terminating with a new line separator. One thing you need to remember is if you are not root, then you should provide the path to store the file in a place where you can write the file, for example, your home directory, which could be like /home/yourusername/something.csv
Hope this helps others to know how to achieve this.
Cyberpanel is a popular web hosting panel that utilizes Openlitespeed as a web server.
Root password for Cyberpanel MySQL is stored under the following file:
/etc/cyberpanel/mysqlPassword
You may find the password with the following:
cat /etc/cyberpanel/mysqlPassword
Now, if you want to avoid finding and typing the root password every time you run MySQL command, you may do the following
Login to your ssh using the root username.
Make sure you are in the root directory for the user root
# cd
Now create a file called .my.cnf with the following content
# nano .my.cnf
File Content
[client]
user=root
password="fydEAhdoMu9WKW"
Now save the file and try commands like the following:
mysqladmin proc stat
It shall work without asking for a password.
NB. Cyberpanel 2.1.2, they are populating .my.cnf automatically. Hence, you can also find your root password from this file using the following while logged in as root:
My disk is full. When using du, I could see my MySQL log folder is taking up all the disk. These files are not mysql-bin files, instead, these are mysql-relay-bin files. How can I truncate or purge these files?
Answer
Mysql creates mysql-bin files which are called binary files for MySQL on the master side. It then streams the binary files to the replicas to reflect the changes. Mysql doesn’t really store the binaries on the replica side, hence it is safe to delete the relay-bin files. Although, there are other safe strategies to accomplish this or never fall into a situation of ‘out of space’.
Firstly, we need to understand, expire_log_days MySQL attribute doesn’t work for the replica. The reason is simple, it doesn’t store the binary files. Hence, using this is worthless for replicas. You can’t use ‘PURGE’ SQL command either for Replica log purging. Replica has a special attribute ‘relay_log_purge’ which purges the relay-bin logs periodically. You can also set replica to follow a specific size of the log file by using ‘relay_log_space_limit’ attribute.
Now at a very certain time, if you want to free up space, other than gross and brutal deleting relay-bin log files, what you can do is the following:
# start your mysql console session
mysql
# stop the slave
stop slave;
# reset the slave
reset slave;
# now start the slave again
start slave;
Now, once the slave is reset, it will start streaming the bin log from the “pos” it has in its queue to populate the pending jobs.
Once the sync is done, you may check the replica status using:
show slave status \G;
Make sure the following two are set to yes:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
If not, you should look at the ‘Last_SQL_Error’ or ‘Last_IO_Error’ section to find out why these are not pushing.
One key bottleneck, every software engineer who uses MySQL, fails to realize, is how to utilize MySQL cache. I have seen people believing the MySQL query cache as the MySQL cache. Sadly, it is not. The query cache is probably one of the worst cache attributes you may enable for your MySQL instance optimization for a high-traffic website.
MySQL Buffers
MySQL utilizes buffers for caching. These buffers are stored in RAM. The key benefit of these buffers is that the changes can also be stored in RAM before flushing the data to disk, along with sync to the replica. Let’s look at an example.
Let’s say, you have selected a post with id 1001
select * from posts where id = 1001
If you have a MySQL buffer, then the result of this query would be placed in the memory.
Now, the subsequent call, let’s say the following:
update posts
set title = 'This is a new title'
where id = 1001
Now, imagine, how the above query will be handled in MySQL? MySQL would write in the RAM, and keep the chunk as dirty to be flushed to disk. Now, that makes the above update super fast to the interactive queries. Because writing to disk would be super slow compared to writing to RAM.
If you live under a heavy load, this is an awe-inspiring tweak. Because this makes your MySQL instance a RAM-based database, with an IO player, which keeps track of your dirty bits, and flushes them when needed. While the con of the approach is that if the system is crashed, dirty bits are lost. Now, we can’t directly say lost, if you are using a system with journaling enabled, that keeps track of the changes, and rolls back.
What is the right Innodb Buffer Pool Size?
There is much misinformation about the size of your buffer pool. MySQL says you should use 80% of your RAM as the pool, which is significantly incorrect. If your database is of size 500MB and the RAM you hold is much larger, then using 80% is quite a waste. You could probably use them for other buffers like a join buffer or a temporary table or a heap table. But unwisely using that for Innodb Buffer is not worthy.
To start with, you can set the buffer pool size to the total size of your database first and let the system run for a day or two. Once done, then you may analyze a few MySQL status variables to find out whether should you increase or decrease. Let’s find out a few details
To get the MySQL status variables, run the following from your MySQL console:
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%';
Now, this should give you a details like the following:
We can use a few metrics from this to determine whether we need a change in buffer or not.
Free Pages
First, we look at the variable ‘Innodb_buffer_pool_pages_free’. It says the amount the free pages you have. If you have set a pretty large buffer pool, you should have a large number of pages in total, hence seeing the number ‘Innodb_buffer_pool_pages_free’ should not make you realize if you are going out of the pool page or not. You may calculate a ratio like the following:
free_page_ratio should not be less than 10% according to my experience until you are running out of RAM. If you have enough RAM, and the ratio is less than 10%, you have fewer free pages, you might want to increase the pool size.
Now, one thing to remember, the value, might stay below 10% all the time, it might not mean you are running out of pool space, instead, you are at the top of the optimization or near to cut off. To determine, if you are out of pool space, make sure to monitor the variable several times of the day and see how often does it change. If it gets lower too often, that suggests you are hitting the boundary and it is time to increase the buffer pool size.
Read Ratio
Next, you need to look at the number of read requests and the number of reads you have performed in total. If you are seeing a lot of read requests and the ratio to reads is higher, then the buffer isn’t enough to store your full database requests in the RAM, and you should increase the value.
Remember, Innodb_buffer_pool_reads means the amount of requests Innodb had to query the disk to get the data from. The value should be less than 1% for maximum efficiency. In my above example, the value is less than .1%, which makes the Innodb performance the best.
Flushed & Wait Free
The other thing, we need to track is that, Innodb_buffer_pool_wait_free. The variable should be near 0 or 0. If the variable is higher, it suggests a situation has happened, where the flushing was essential to free pages. Even if you have a good read_ratio, but if the variable shows a large number, then you need to increase the buffer pool size to make sure we do not need to free pages at the peak times.
Continuous monitoring is essential to perfectly use Innodb Buffer Pool. It is an extremely essential part of MySQL-based software and should be used wisely. Proper usage can excessively decrease your server CPU cost, and maximize the overall performance.
For example, you manage a high traffic website, that utilizes an abstraction layer like an ORM to manage MySQL queries. Now, as a DevOps/System Admin, it becomes difficult for you to get a stat of which MySQL query being overused in the scenario. For these cases, one way, you may get some idea on what being overused, is called ‘MySQL General Logs’. Remember, it is very much different than the MySQL Slow Query Logging. It is not essential to have a slow query in the system to determine if your mysql is boggling. It is very much possible, there are queries, that take very small amount of time, but starves your CPU by executing many times and performs the same operation. Once you are able to identify them, you may utilize any Hashmap based caching strategy like Memcache or Redis or Simple file cache to reduce your load down on MySQL instance or cluster.
First, we create a query logging file and set the right permission:
Once the file creation is done, now we can enable general log either by using mysql shell, if you would like to avoid restarting your mysql instance or in my.cnf file to keep the change permanent. A point to note, you should not do query logging all the time, as it decreases MySQL performance by 15-25%, which might hurt your overall production performance, plus the size of log will cumulatively increase if you have a server that performs over a thousand or more queries per second.
# Type in your shell prompt
mysql
# this will open your mysql shell, you may run mysql commands as below:
mysql > SET global general_log = 1;
mysql > SET global log_output = '/var/log/mysql_query.log';
This should immediately advise mysql to push the logs to /var/log/mysql_query.log.
Now, if you observe the file, you may see the queries are coming up so quickly that you may hardly find anything out from it. The file has no output until you aggregate the result. If you have a large file, a better way to aggregate result by using Lotstash and Elasticsearch. We won’t do that here, that would be a topic for another blog post. We would instead use, some basic shell aggregation to see if we can determine anything useful from this. You may use the following tool, that list the last 10000 lines, then sort, and group the unique lines with the count and order by ascending to put the most frequent query at the end of the line:
This will help you by giving the top most used query in last 10K queries. If the number is more than 5%, you need to pay attention to that. If it is the same query, that means, you may use a Hashmap based caching technique to reduce database boggling and improve performance.
There are times, you may see the following error in your MySQL/MariaDB based Cpanel server:
[ERROR] Can't open and lock privilege tables: Table 'mysql.servers' doesn't exist in engine
The issue is most likely related to your Innodb tablespace got corrupted, and hence some tables under the mysql database got locked out as some of them use Innodb storage engine. One of the outcome of the symptom is, if you try to add a user to a database, it doesn’t add or show the green notification any longer in cpanel mysql databases section. Instead it just stops.
The only and best way to properly fix this would be restore the ‘mysql’ database or just the ‘servers’ table from your backup. If you don’t have one, you may just create the ‘servers’ table using the following SQL statement:
CREATE TABLE `servers` (
`Server_name` char(64) NOT NULL,
`Host` char(64) NOT NULL,
`Db` char(64) NOT NULL,
`Username` char(64) NOT NULL,
`Password` char(64) NOT NULL,
`Port` int(4) DEFAULT NULL,
`Socket` char(64) DEFAULT NULL,
`Wrapper` char(64) NOT NULL,
`Owner` char(64) NOT NULL,
PRIMARY KEY (`Server_name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
You may require to drop the table first. Now, if you can’t do this either, then there is only one way left, is to uninstall your MariaDB installation, and let Cpanel/WHM to install them for you.
Now, you may install the latest MariaDB from WHM >> MariaDB/MySQL Upgrade and proceed accordingly. This should install the latest for you with a fresh ‘mysql’ database for you. But it will not alter your other data files, means your other databases should be fine.
One thing, you need to remember, after a fresh mysql installation with the old data files, you will have the authorizations missing. You would have to recreate the database users manually to get the privileged table filled up.
If you are here, that means, you probably have panicked the same way, I did around 12 years back. I lost my ib_logfile0/ib_logfile1/ibdata1 all at once for a server that excessively utilizes Innodb tables. I had to recover vital data from the same situation today on a random request who does not have backups, and thought it is better to keep this as a document for future.
One key purpose of utilizing Innodb tables instead of MyISAM is that, the benefit on writes. It always outperform MyISAM in writes due to the use of extra efficient buffers. But, this also causes Innodb to vulnerable from crashing. As Innodb stores some sensitive data to 3 specific files, loosing them, also looses some serious mapping instruments for the database engines to recognizes Innodb table structure and data.
Who can follow this technique?
If you have lost any of ib_logfile0, ib_logfile1, ibdata1 or all of them, but still manages to keep the database folder intact with the .frm and .ibd files (which you would, if you have accidentally deleted the log file or the data only) and also have the following option NOT DISABLED in your mysql configuration ‘innodb_file_per_table’. This option is enabled by default, until you are explicitly disabling this to increase performance. A suggestion: only do this, if you keeping real time backups of your databases. Otherwise, it is better to have this enabled
What is ‘innodb_file_per_table’?
Primarily the tablespace stores and uses data from system tablespace for Innodb. But, as this creates a single point of failure from ibdata and log files, Innodb by defaults also stores the tablespace in table’s own data file, which is .ibd file. That means, if I lose the ibdata/logfile mappings, I can still use the .ibd file to restore my tablespace and do the schema to data mapping only if I allowed innodb to store these information to the database’s own .ibd file. You may read more about the parameters from MySQL documentation:
How to Recover an Innodb Table from database files only?
There are two steps to this process. One is to identify and recognize the database schema from the frm file and then basically find a way to import the tablespace from .ibd file and introduce it to innodb engine system tablespace.
First Step First: How to get the schema from .frm files?
First, you must install mysql-utilities tools to get access mysqlfrm tool, you may get the instructions to install this here:
Once this is done, now you have two options to read mysqlfrm files. My favorite way is to use the ‘diagnostic’ attribute. To achieve this, run the following:
I assumed, your database name is ‘your_database’ and the table you are trying to recover is ‘assets’. The above command will return you the schema of ‘CREATE TABLE’ you need to use. First, create a new database, and run this on the SQL console to generate the table first on the new database.
Second Step: Get your data and mapping back from .ibd to system tablespace
Once the database has the table, it will also create a .frm and .ibd file for you. What we need to do, is to first, make it forget the existing .ibd file it created, sync the .ibd file from our collapsed database, make the mysql innodb engine to recognize tablespace from the backup tablespace of this .ibd file and store & use it from system tablespace. These lines are complex, and might sound a bit difficult. No worry, let’s do it.
Run the following command first to let it forget the .ibd it has created now:
alter table assets discard tablespace;
Remember the following, our table name is ‘assets’. If you have a different table name, make sure to replace this accordingly. What this has done, is removed the assets.ibd file it created in /var/lib/mysql/new_database/ folder as we asked him to forget the existing .ibd file. Now we first need to copy the backup/old .ibd file to this location with the correct permission. I would use rsync to make sure permissions remains intact here:
Once this is done, we know, .ibd contains a backup of our original tablespace. We only need to make mysql & innodb recognize this. To achieve this, you may do the following from the Sql console:
alter table assets import tablespace;
If it throws a warning on not being able to file the .cfg file, you may forget it, because it is not essential to have a .cfg to recognize permissions/configurations.
If everything runs well, you should see your rows are back. It’s because innodb has now fetched your tablespace data from .ibd file to system tablespace and it can now recognizes the mapping to your data, viola! All you now need is to repeat the process for all of your innodb tables, and recover the whole database.
Mysql provides a set of utility tools that can be used to recover your data from Mysql data files. One of them is ‘Mysqlfrm’. This tool is not given in primary MySQL bundles, instead it comes with Mysql-utilities.
This package can be installed from ‘mysql-tools-community’ repo, those are available from MySQL Yum Repos
Command would be:
yum install mysql-utilities
This would also install another python package called ‘mysql-connector-python’ for you form the ‘mysql-connectors-community’ repo automatically. There is one catch. Sometimes, due to python version dependencies, you may fail to connect to mysql through the automatically detected mysql-connector-python that is automatically installed by mysql-utilities. You may know that if you are seeing the following error when you type mysqlfrom in the command line:
# mysqlfrm
Traceback (most recent call last):
File "/usr/bin/mysqlfrm", line 27, in <module>
from mysql.utilities.common.tools import (check_python_version,
ImportError: No module named utilities.common.tools
For these cases, you may install an older version of mysql connector for python, using the following before installing mysql-utilities:
yum install mysql-connector-python.noarch
This would install an older version of mysql connector that works better with Python 2.7 or similar.
Once the above is done, you may now install mysql-utilities using the following back again:
yum install mysql-utilities
As you have already installed the connector, this won’t try to reinstall the mysql connector from dependencies and use the other one that you got installed.
Now you may use the mysqlfrm tool to read your frm files and recover the table structures if required. Here is a great article from 2014 and still valid on mysqlfrm use cases:
This would be a simple step by step post for the help of my customers. You require two tools for this.
i) putty – ssh client ii) WinSCP – File transfer client over SSH (You may use FTP or File manager as well)
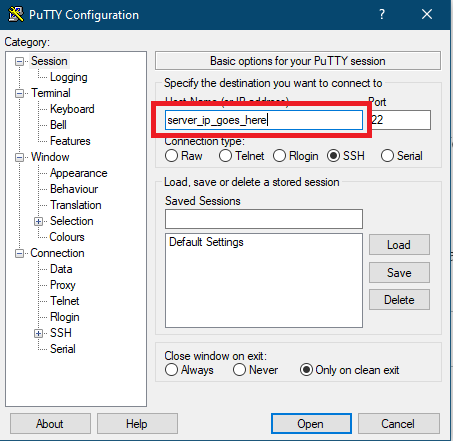
Once you download putty, open it, and use your server’s IP in the Host Name section:
Now, click on open. In the prompt, type ‘root’ as login as and enter. Then type the password and enter. If the password for the root is right, it will login to the command shell prompt or else it will put you in the authentication error console.
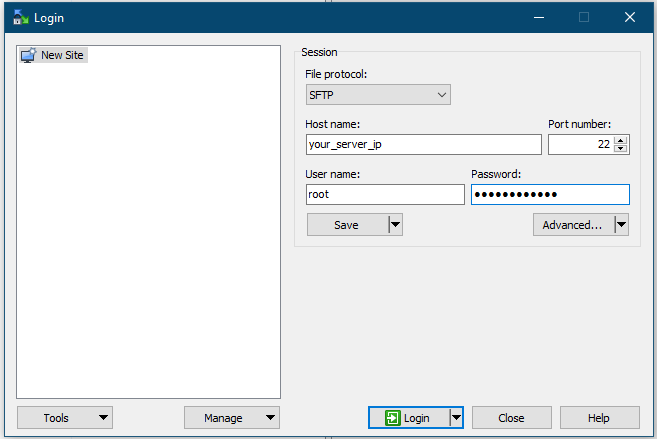
Now, open WinSCP to login to your server using the same manner of SSH. Once done, transfer your sql file to the home directory of root.
Login to your server using WinSCPWinSCP Transfer
To transfer the file, navigate the sql file from your desktop on the left side and then drag it to the right side of WinSCP window. That will start the transfer. Remember the path of the destination on the server. Path is shown in the red marked area in the image.
Once the file is transferred, come back to putty, and change directory to the path you had noted in WinSCP, in our case, it is /root/
cd /root/
mysql -uusername -ppassword your_database_name < your_sql_file_name.sql
Remember the following. Your mysql username should go right after ‘-u’ without any space and the mysql password should be the same without space. Replace the ‘your_database_name’ with your original database name in the server and ‘your_sql_file_name.sql’ with the exact sql file name that you had uploaded.
Now if you allow sometime, the command should complete after the restore. If it returns any error, you would need to attend them to do a complete restore.
Suppose, you have a live Ecommerce system. What you want to see, is how well your revenue is performing comparing to yesterday. But if you are comparing with the total revenue of yesterday, then this won’t be an efficient metric until you reach the end of the day. In real scenario, what you would like, is to compare it with the identical time it is happening right now. For example, if it is 7.19 PM now, then you want to compare either of the following two and show the trend:
i) Revenues within 00:00 – 7:00 PM yesterday to revenues within 00:00 – 7:00 PM today or ii) Revenues within 00:00 – 8:00 PM yesterday to revenues within 00:00 – 8:00 PM today (remember, it is 7.19 PM, so the counter and comparison will continue to flow when you get new order on this case)
Both of the way of seeing trend is useful, depends on your choice, but if you are comparing the metrics with the full of yesterday and the half way through to today, this might not be as useful.
How To Do This In Meatabase?
Please remember, I would be doing this in Metabase. Metabase is an open source data analytical and visualization tool written in Java. It is simple, fast and efficient tool for all square use cases in data analytics. I am using a ‘Reformatted’ real time MySQL database as the data source, hence the query can be used in plain MySQL databases to see results.
Note: We can’t do this with the simple query of Metabase, hence, we have to use the Native query support of Metabase. If your Administrator has limited your access to Metabase to Simple & Custom query, then you can not do this until your Administrator allows you so.
Building The Query
Let’s assume, our orders lie in ‘orders’ table, order creation dates are given in ‘date_created’ column, along with order status and the total value of the order is stored separately under status and total column.
First, we write the sum of the total column with the mysql aggregation function ‘sum’ and set a variable ‘date_created’ based the on the date_created column of orders table as following:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
Now, if you want to use the ‘Trend’ in Metabase, then the query must have ‘Group By’ a timeseries based on which it shows the ‘Trend’ metrics. And we know, that our group by timeseries going to be ‘date_created’. We also know that our conditions of selecting the rows, going to be under the ‘WHERE’ statement, so we will keep it as blank for now. So the query, goes as following now:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
WHERE (
# Our conditions will follow here
)
GROUP BY date(`orders`.`date_created`)
ORDER BY date(`orders`.`date_created`) ASC
We are done with the basic. Now, let’s fill up the WHERE statement. First, you may want to filter out certain ‘status’ of the orders in case you have many. You first, fill that up as following:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
WHERE (
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing')
)
)
GROUP BY date(`orders`.`date_created`)
ORDER BY date(`orders`.`date_created`) ASC
In my case, we are filtering if the order status is either completed, confirmed or processing. We are discarding other statuses like on-hold, or pending or abandoned cart.
Now, let’s think for a moment. We have to compare two time series, that means, we have to first, create an identical time differences. Let me give an example for better understanding. If we are trying to find out, the revenues between 00:00 – 20:00 yesterday and 00:00 – 20:00 today, then we need to have two conditions in WHERE statement for each of them, and they should select all the rows from both conditions, which necessarily means, it would be a ‘OR’ statement. For both cases, we need to select the order statuses, that would necessarily mean something like the following:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
WHERE (
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing')
)
Or
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing')
)
)
GROUP BY date(`orders`.`date_created`)
ORDER BY date(`orders`.`date_created`) ASC
Does the above make sense? If not, soon enough it would be, let’s move on to the next step. Now, how can you align the time to match the hour we have now in SQL query? MySQL curdate() returns the current date, which is today at 00:00 So, if I know the difference of hours left for today, and subtract that from curdate(), that would give us the hour it is now with the date of yesterday. Here is the example:
This is 20th hour, so if we subtract 20 from 24, it would be 4. Now, we subtract 4 from curdate():
10-6-2020 00:00 - 4 Hour 09-6-2020 20:00 which basically is the same hour we are on, of today 10-6-2020 20:00 hour. Simple, isn’t it?
Now, how to write this in SQL query? Let’s see
First, we get 09-6-2020 00:00 Hour, this can be done as following in MySQL with negative Interval of 1 Day from current date.
date_add(curdate(), INTERVAL -1 DAY)
Next, we get 09-6-2020 20:00 Hour using the following:
date_add(curdate(), INTERVAL -(24 - hour(now())) HOUR)
See, how I am calculating the Interval Hour, I am using the MySQL function 'hour()' on another function 'now()' to get the hour we are on, which is giving me 20, then we are subtracting from 24 as 24 hours a day, the result is giving me 4 here. So the output going to be 20:00 hour.
Now, for today, we first need 10-6-2020 00:00 Hour, which is simply:
curdate()
then, the target time is basically the now() function:
now()
We now have all 4 parts of it, here is the completed statement going to be only for the time selections:
For Yesterday:
str_to_date(date_format(`orders`.`date_created`, '%Y-%m-%d %H'), '%Y-%m-%d %H')
BETWEEN str_to_date(date_format(date_add(curdate(), INTERVAL -1 DAY), '%Y-%m-%d %H'), '%Y-%m-%d %H') AND str_to_date(date_format(date_add(curdate(), INTERVAL -(24 - hour(now())) HOUR), '%Y-%m-%d %H'), '%Y-%m-%d %H')
For Today:
str_to_date(date_format(`orders`.`date_created`, '%Y-%m-%d %H'), '%Y-%m-%d %H')
BETWEEN str_to_date(date_format(curdate(), '%Y-%m-%d %H'), '%Y-%m-%d %H') AND str_to_date(date_format(now(), '%Y-%m-%d %H'), '%Y-%m-%d %H')
By adding the above to our basic and simple status selection statements:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
WHERE (
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing' OR `orders`.`status` = 'on-hold')
AND str_to_date(date_format(`orders`.`date_created`, '%Y-%m-%d %H'), '%Y-%m-%d %H')
BETWEEN str_to_date(date_format(date_add(curdate(), INTERVAL -1 DAY), '%Y-%m-%d %H'), '%Y-%m-%d %H') AND str_to_date(date_format(date_add(curdate(), INTERVAL -(24 - hour(now())) HOUR), '%Y-%m-%d %H'), '%Y-%m-%d %H')
OR
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing' OR `orders`.`status` = 'on-hold')
AND str_to_date(date_format(`orders`.`date_created`, '%Y-%m-%d %H'), '%Y-%m-%d %H')
BETWEEN str_to_date(date_format(curdate(), '%Y-%m-%d %H'), '%Y-%m-%d %H') AND str_to_date(date_format(now(), '%Y-%m-%d %H'), '%Y-%m-%d %H')
)
GROUP BY date(`orders`.`date_created`)
ORDER BY date(`orders`.`date_created`) ASC
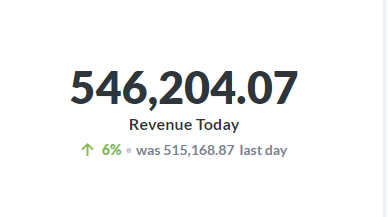
Simple, huh? Indeed, it is. If you run this query in phpmyadmin, or your mysql console, you will see the revenue amounts from the yesterday till the hour we are running through at this moment of today. But in Metabase, you can get a beautiful ‘Trend’ number metric with it. Just go To Visualization >> Trends to show you the Trend Number Metric for this as following:
It is cool to see how good or bad you are doing by this hour than yesterday.