This would be a simple step by step post for the help of my customers. You require two tools for this.
i) putty – ssh client ii) WinSCP – File transfer client over SSH (You may use FTP or File manager as well)
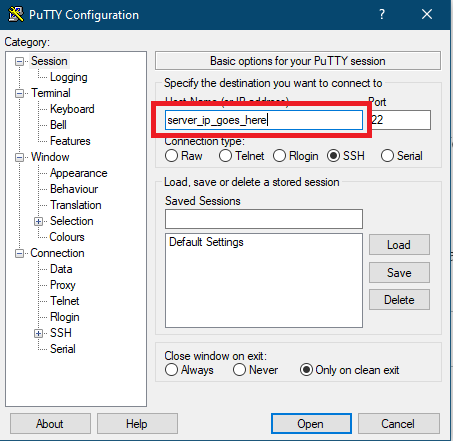
Once you download putty, open it, and use your server’s IP in the Host Name section:
Now, click on open. In the prompt, type ‘root’ as login as and enter. Then type the password and enter. If the password for the root is right, it will login to the command shell prompt or else it will put you in the authentication error console.
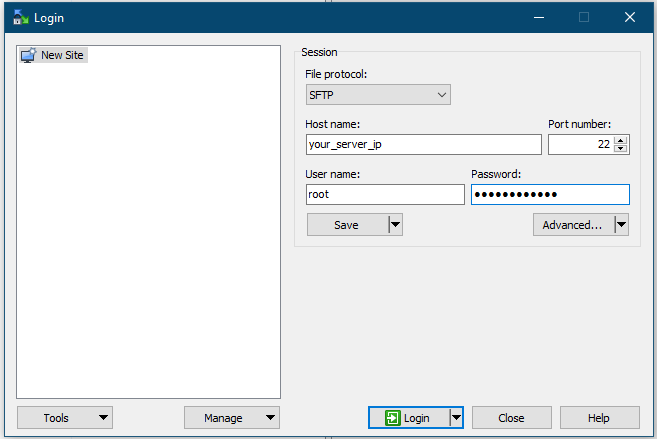
Now, open WinSCP to login to your server using the same manner of SSH. Once done, transfer your sql file to the home directory of root.
Login to your server using WinSCPWinSCP Transfer
To transfer the file, navigate the sql file from your desktop on the left side and then drag it to the right side of WinSCP window. That will start the transfer. Remember the path of the destination on the server. Path is shown in the red marked area in the image.
Once the file is transferred, come back to putty, and change directory to the path you had noted in WinSCP, in our case, it is /root/
cd /root/
mysql -uusername -ppassword your_database_name < your_sql_file_name.sql
Remember the following. Your mysql username should go right after ‘-u’ without any space and the mysql password should be the same without space. Replace the ‘your_database_name’ with your original database name in the server and ‘your_sql_file_name.sql’ with the exact sql file name that you had uploaded.
Now if you allow sometime, the command should complete after the restore. If it returns any error, you would need to attend them to do a complete restore.
Well, this is an interesting topic. Earlier today, I answered the same question in a Elasticsearch Community Group in Facebook, thought to keep this documented as well.
Primarily, if you are aware of how Elasticsearch is storing data (The document like), you might think, it is a full fledged NoSQL database, but you need to know, it is not. If you have looked at several NoSQL databases, you might already be thinking, there is probably no standard definition of NoSQL databases, which is partially true, again, there still is definition of database management systems, where it doesn’t fit. Does that mean, we can’t use ES as the primary data store? No, that’s doesn’t mean that. You certainly can, but there are use cases. Let’s look at couple of points before we conclude.
Database Transactions
ES has no transaction. Even the algorithm that ES implements, Lucene Search, which has transaction in the original design, but ES doesn’t have any transaction. When there is no transaction, the first thing you need to remember, it has no rollback facility. That also means, every operation is atomic by design, and there is no way to cancel, abort or revert them. This also means, you have no locking standard in the system. If you are doing parallel writes, you need to be very careful about the writes here because ES is not giving you any guarantee to parallel writes.
ES Caching Strategy
Elasticsearch is a ‘near real’ time search engine. It is not a ‘real’ time search engine. It has a caching standard, that refreshes every 1 second. This is ‘by design’ of Elasticsearch. So, what’s the problem with it? The problem is, you may get tricked by the ES cache if you are immediately asking for a read for a quick write operation and it is within 1 second. But as most of the cases, ES is not written much often (Since most of the people do not use it as primary storage), most of the people thinks it is real time. But it is not. It’s cache can trick you in intense cases, where writes won’t be immediately available to you for read.
User Management
ES user management is no where near to a full fledged DBMS, only because ES doesn’t need to. They have never announced themselves as a NoSQL DBMS, hence they do not require to add the functionality in full square. They only implements the facilities that ES Ecosystems require.
So … ?
So, what does all these mean to you? If you have an extremely large read featured application, where updates are very rarely or occassionaly done, then you can definitely go with ES as your primary document storage engine. But if you have a write oriented application, requires complex user management or parallel threads require write access, then you better be choosing a standard DBMS for your business and use ES as secondary data store for your analytics and searches.