You may have raw images in your system coming from some bare metal VM, like KVM/Vmware. You may mount them directly to the host machine without attaching them to a VM. To do so, you need two things:
Partition to mount
Sector size of the partition and the first position of the partition.
Both of these, can be derived using a command called fdisk with attribute l as the following:
[root@vps5 vpsextra]# fdisk -l mhdevelopment.img
Disk mhdevelopment.img: 268.4 GB, 268435456000 bytes, 524288000 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000f1752
Device Boot Start End Blocks Id System
mhdevelopment.img1 2048 523241471 261619712 83 Linux
mhdevelopment.img2 523241472 524287999 523264 82 Linux swap / Solaris
You have new mail in /var/spool/mail/root
[root@vps5 vpsextra]#
Here, we are trying to mount an old image of mine, called ‘mhdevelopment.img. I would like to mount the partition that is not swap, which is namely ‘mhdevelopment.img2’ here. This partition starts from 2048 and the sector size is 512 bytes.
So to mount the partition, you can now use the following command:
sudo mount -o loop,offset=$((2048 * 512)) mhdevelopment.img /mnt
This will mount the the partition mhdevelopment.img1 to /mnt. If you want to change the mount destination, you may do this at the end in replace of /mnt to wherever you want this to be.
After you have completed updating your yum, you saw the kernel got updated, and hence restarted the server to take the new kernel. But you find out that the server has never come online. Once you visit the KVM or Serial Console (SOL) of the system, you could see, your system is booted to ‘grub>’ console instead of booting from disk. How can you fix the system now?
Solution Intro
This specific issue can appear for any linux server, along with many reasons. Although, if you are running an server from OVH and had faced a similar issue, the boat I am going to show you can navigate to destination. Please note, in many other case of similar situation, you might end up fixing the grub with the same solution.
What and How the Problem Happened
OVH has an interesting strategy of booting. They follow everything through network PXE, even if it is not ‘netboot’, but just the local drives. For this to work out, you need PXE to take the latest grub details pushed once a kernel is updated. This is one reason why, OVH also supplies a custom kernel from a cusstom repo. Although, if you are using the stock kernel, you might come up with a situation, where the latest grub hasn’t been pushed to PXE and your system fails to boot from drives. It then puts you in the ‘grub’ of network.
How to Fix the Problem
Now, one thing is clear, after you completed a kernel update, your grub is broken due to the latest machine code is not available to the booting system. You can go and follow a regular grub repair method for Grub 2, to fix the situation. A couple of things to remember, as your system’s grub is failing to load, you have to use an independent rescue kernel to fix this, this could either be from a personal network repository or a rescue disk available from your datacenter’s location, like ovh has one. Another thing to remember, is that, if you are using CentOS 7 or Ubuntu with UEFI system, using mdadm or linux software raid, it is highly likely, your boot efi is placed in a non raid partition. Preferably in the first drive’s first partition. You can always verify this from your fstab file.
So the first job, is to boot your system into the rescue disk/cd/kernel. I assume you have done that with no difficulty. Once done, first mount your partitions. In OVH cases, it loads the mdadm automatically. In my case, it was /dev/md2.
mount /dev/md2 /mnt
# check what partition is used for /boot/efi
nano /mnt/etc/fstab
# in my case, it is /dev/nvme0n1p1 (It is a NVMe SSD, and the first partion is used for efi storage
mount /dev/nvme0n1p1 /mnt/boot/efi
Once we have mounted the partitions successfully, you may now chroot the system. Before chrooting, you want the dev, proc and sys to use the /mnt partitions respectively:
mount --bind /dev /mnt/dev
mount --bind /proc /mnt/proc
mount --bind /sys /mnt/sys
If these all goes well, now we can chroot the system:
chroot /mnt
Now you have successfully changed the root directory of the rescue kernel to the original drive’s root. All you need to do, is to remake the grub config, that will immediately generate the grub.cfg file and sync the machine code:
# we know grub.cfg is available in /boot/grub2/grub.cfg
grub2-mkconfig -o /boot/grub2/grub.cfg
# once this is finished, we have to make sure, grub is also installed for both disks, for my case, these are /dev/nvme0n1 and /dev/nvme1n1
grub2-install /dev/nvme0n1
grub2-install /dev/nvme1n1
If you see the response is ‘No Error Reported’, then you are good go. You may now reboot your system back to hard disk, and can see your grub is able to load the latest kernel you installed from the original hard disk. Remember, for safety, you should umount all the partition, to avoid any data loss due to OS page cache:
First, let’s see why do we need to copy a disk over SSH. One is of course for backup. For example if you have a VM on a LVM partition. You want to keep a copy of the block level backups, you prefer to create a snapshot of the lvm partition and then copy the disk as an image to your backup server. The other being quite the same, but for different purpose. What if you want to migrate a VM that you have created on an LVM partition, and then you want to migrate it as a raw file to another server? Or a LVM partition to another server? For those cases, the technique is pretty awesome.
Copy The Disk to a RAW Image
First, let’s learn how can copy a disk as raw image.
For example, you are sitting in your backup server. And you want to copy a disk or lvm partition or a partition of a disk, from a remote server to your backup server. And you want to keep the copy of the image, then you may run dd command as following from your backup server:
In our case, 10.10.10.10 is the IP of the server, that partition/disk currently reside. We are trying to copy a LVM partition namely: /dev/vg0/v1092-kdkdksjuekksq, just replace this one with the one your desired lvm partition. You may also do this for a disk like /dev/sda, the command would be like the following then:
Now as you have copied the disk/partition, you may look at what the partition holds by checking the data inside it. To know, how to mount a raw disk image, you may check the following:
You may either copy the disk directly to a secondary disk you have on the backup/migrated server or dump the image that you copied to another disk/partition of same size or bigger. To copy directly a partition /dev/sda from another server, to a backup server with the secondary disk /dev/sdb, you may do the following:
There are times, when your application may throw error like the following in Linux:
dial unix /tmp/padapter.usk: socket: too many open files
It could only contain the following, without relating the fast message:
socket: too many open files
How to Fix
This error appears because Linux file system puts a limit of amount of open files you may use at a time. It is calculated based on a variable system set is called ‘file-max’. File System also keeps a variable called ‘file-nr’ to count the number of file you have in usage. To quickly look at your usage, you may run the following:
The first number is the amount of file descriptions in use in your linux system. Here the last number is your hard limit and the second number is your soft limit. The hard limit is your file-max. To know your file-max value, you may run the following:
As we see, the limit is set to 265535 and the usage is 4512. If the usage goes up for some reason, for example an infinite loop on the cache creation, you may run out of file system open limit and hit the error. To set the value fir file-max, we will take sysctl.conf in consideration.
First open sysctl.conf file with the following:
nano /etc/sysctl.conf
Add the following line and save:
fs.file-max = 524280
This will increase your open file limit to 524280. Now to reflect the change immediately, you need to run the following:
We at Mellowhost has been utilizing R1Soft CDP backup for last 8 years. R1Soft has been a great backup tool even though the tool is immensely resource hoggy. At different times we had gone through different situations to handle our backup servers efficiently. After all the hiccups with backup nodes, we ended up efficiently configuring 3 backup servers of 3 different configuration
backup1 = It contains 12TB file system on a RAID 0 array. It copies data to a BTRFS compressed drive once a week to keep the data safe if RAID 0 dies. This server uses RAID 0 for faster drive verification and block scanning by r1soft. This server hosts servers that requires frequent backing up and can sustain a loss of a week data (Less important data). As the server performs really fast due to being RAID 0, we can run multiple r1soft threads at a time including disk safe verification and block scans.
backup2 = It contains 30TB file system in RAID 6 hardware array. This is used for hosting our VPS backups. This server is a seriously large one to keep backups of our enterprise VPS clients.
backup3 = It contains 16TB file system in RAID 10 hardware array. This server is hosted in a East Coast American Location. It is our off network backup server and keeps backups for East Coast servers too.
One of the key factor in designing a backup server is the size and the location. Need to keep in mind that CDP 3 takes more space than CDP 2 for unknown reason while still being a differential backup solution, not just an incremental. Location of the server matters due to the network speed. If you are hosting your server a lot far than the server network, it may take longer time to complete the initial storage. Due to the latency it may fails to perform as fast like 1Gbps even if both network supports it. Just for an example, if you are backing up your data at 1MBps speed, it would take 12.13 days to complete backup of 1TB data [ Calculation: (((1024 x 1024) / 60) / 60) / 24 = 12.13 days ]. A 100Mbps port can give you speed upto 10MBps, while you can have 50MBps+ speed if you are using a 1Gbps network roughly. So why does the speed matter? If you are backing up your initial data in 13 days, that doesn’t mean it will be the same all the time. Your second backup would take much less amount of time as it only needs to upload the differential backups. That is true! But the problem will come when you require to do a bare metal restore. If your server requires a disaster recovery, you would then need 13 days to restore your server to the original state. Your customers won’t sit down for 13 days! While creating backup, it is important to think about disaster recovery too. How fast are you going to be able to restore the backup is an important concern while designing your disaster recovery solution.
I always recommend users to choose a 1Gbps network with a latency below 2ms if you want to have a good disaster recovery solution. This can guarantee a faster bare metal restore when needed.
The second key factor while creating the R1soft backup server would be to choose the RAID. If you are thinking to create r1soft backup on a non-raided solution, I think you should drop off your idea. RAID isn’t necessarily always use to keep your data safe, it can also be used for performance. Keeping a RAID 0 or striping in general is must for a R1Soft server. Otherwise, every couple of times, you are going to see a lot of stalled processes doing ‘disk safe verification’ ‘block scan’ etc etc and not able to keep the backup up to date or canceling processes due to duplicate backup process (Old one taking too long to complete). It is better not to choose RAID 5. I particularly didn’t try RAID 5, but I have used RAID – Z on ZFS file system, which was seriously slow for my work around. I switched the server later on to RAID 0 and BTRFS compression to keep a weekly backup which tremendously improved the R1Soft performance. We at later time, worked to create more backup servers with hardware RAID WB cache and battery backed unit to give us more performance benefit while creating and restoring backups. These servers have been performing tremendously well with R1Soft. They can also be called good disaster recovery node.
Last, I recommend you to understand that backup isn’t just keeping a copy of your data of your online existence. It is important to design a disaster recovery solution instead of just creating backups. If you are simply into creating backups, you probably don’t need R1Soft or any high end servers instead simple Rsync would work fine. But to create ‘Disaster Recovery’ solution, you need high level planning, good hardwares and good cost estimation. If you are leaving behind in any, you will probably fail to create a good disaster recovery solution that actually ‘works’.
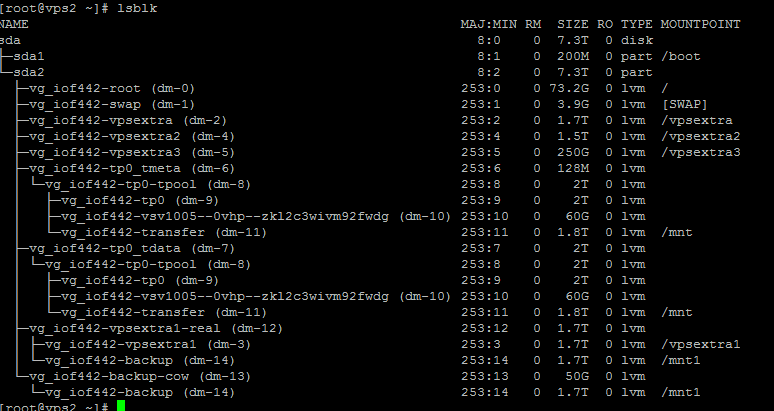
Sometimes, you will see the error thrown in dmesg or /var/log/messages are mentioned in dm-number format, while you manage the disk using lvm logical volume name. This is because lvm logical volumes are designed through kernel device mapper technique and kernel recognizes volumes using dm numbers. There is a tool to list all the device mappers used for block devices under Linux. Simply type the following to list the maps:
# lsblk
It shall show something like the following:
There you can see the dm number for each lvm volume is listed under first bracket. For example the swap in this server is created with LVM with the name vg_iof442/swap and has the dm-1 mapping.
Question: How to find iops usage of a linux server?
Answer: Use iostat. Iostat is a tool comes with the ‘sysstat’ package. If you type iostat on your CentOS/Redhat server and it says the command not found, you can install sysstat to avail the iostat command.
yum install -y sysstat
An example iostat usage case could as simple as following:
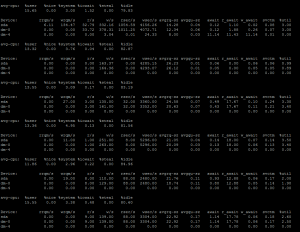
iostat -x 1
-x tells iostat to give extended statistics which is required to find read/write iops individually. And the 1 tells iostat to repeat the command every 1s.
An example output would be like the following:
If you look at the output, the colum r/s would say the read iops and the colum w/s would say write iops. If you are using simple ‘iostat 1’ then the column tps should show the total iops of the disk in use.
If you are using a spinning disk, and if you are getting anything around 150-200 cumulatively, you are probably hitting the iops limit. With raid, the number would change according to your raid choice. Although, the number can increase in case of using Writeback SSD Cache, Hardware RAID Cache or Pure SSD disks. Most important benefit of using SSD is not essentially the amount of throughput it gives in a practical environment instead the amount of IOPS it can sustain is phenomenal.
Question: What is Kondemand? Why do I see a lot of Kondemand process in my process list?
Answer: Kondemand is the process used for automatic CPU scaling on multi core linux system. It automatically reduce/drops the CPU clock speed to power usage when the CPU is not in use. This is done through scaling_governor available on linux. To see if your scaling_governor is set to ‘ondemand’ or not, you may use the following command:
If your CPU is showing ‘ondemand’ scanling governor then the kondemand kernel process is active and will reduce your CPU clock speed on fly to reduce power usage. You can change this settings to performance on fly using the following small shell code:
for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f $CPUFREQ ] || continue; echo -n performance > $CPUFREQ; done
There is a linux service called CPUSpeed, this can tune your scaling governor back to ondemand after the reboot. You may shut it down:
service cpuspeed stop
chkconfig off cpuspeed
You may check your CPU speed is restored to the original through the proc filesystem:
Question: Can you run fsck on a disk image or raw file?
Answer: I believe you are referring to KVM disk image/raw files. It could be the disk image created from a dd clone. The answer yes, you can run fsck on a disk image. You can also use other fsck attribute as required as following:
fsck.ext4 -fyC /somefile.raw
Remember to use specific partition fsck binary, here, we have used ext4 binary for a ext4 file system loaded on the image file. Running badblock program on an image file can be bad. You may use -c (small c) to run badblock check with the fsck:
fsck.ext4 -C -fyc /somefile.raw
This sometimes create undesired results and not advisable.
Question: What other option do I have?
Answer: You can mount the image using loop back device and then run the file system check. This can be done using kpartx as described in this post: How to: Mount raw VM disk images (KVM/Xen/VMW)
I had an interesting problem earlier today. While running r1soft backup, dmesg was throwing some I/O like the following:
Dec 28 09:28:43 ssd1 kernel: [36701.752626] end_request: I/O error, dev vda, sector 331781632
Dec 28 09:28:43 ssd1 kernel: [36701.755400] end_request: I/O error, dev vda, sector 331781760
Dec 28 09:28:43 ssd1 kernel: [36701.758286] end_request: I/O error, dev vda, sector 331781888
Dec 28 09:28:43 ssd1 kernel: [36701.760992] end_request: I/O error, dev vda, sector 331780864
They didn’t go out after multiple file system checks. That left me no choice other than finding what’s actually in that sector. I could see the sector numbers was increasing by 128 up 10 sequential logs. That makes to understand it could be a specific account causing the errors.
EXT file system comes with an interesting tool called debugfs. This can be used on mounted file system and can be used to track down IO related issues. Although, you require to do some calculation first to convert sector to block number of a specific partition before you can use debugfs.
The lowest sector number in the log was ‘331780864’. First I tracked down the partition where this sector lies. This can be done using fdisk -lu /dev/disk (Make sure to use -u, to ensure fdisk returns the sector numbers instead of cylinder number)
#fdisk -lu /dev/vda
Disk /dev/vda: 1342.2 GB, 1342177280000 bytes
16 heads, 63 sectors/track, 2600634 cylinders, total 2621440000 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0002f013
Device Boot Start End Blocks Id System
/dev/vda1 * 2048 411647 204800 83 Linux
/dev/vda2 411648 205211647 102400000 83 Linux
/dev/vda3 205211648 209307647 2048000 82 Linux swap / Solaris
/dev/vda4 209307648 2621439999 1206066176 83 Linux
Now, find the Start Number < Our Sector number to detect which block contains our desired sector. In our case, it is /dev/vda4. Once done, we need to numeric sector number specifically for this partition, which can be done by subtracting our sector number with start number of the partition. In our case:
331780864 – 209307648 = 122473216
That means, our sector lies in 122473216th sector of /dev/vda4.
From the two relations block/bytes and sector/bytes, find sector/block : 512 / 4096 = .125
Now, calculate the block number of 122473216th sector: 122473216 x .125 = 15309152
We can now use debugfs to determine what file we have on that block number as following:
debugfs /dev/vda4
On the debug prompt, type:
debugfs: icheck 15309152
Block Inode number
15309152 2611435
This will show the inode number of the desired file. Use the inode number to run:
debugfs: ncheck 15309152
Inode Pathname
15309152 /lost+found/#29938847
This will show you the desired file that is actually causing the issue. In my case, I could find files that were corrupted in some old fsck, were stored in lost+found and they were missing magic number/incomplete files. Once I had deleted all the files from lost+found, my issue was resolved. Viola!