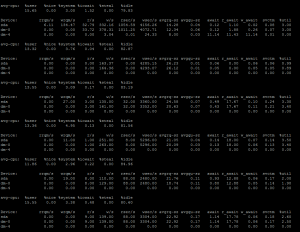
I had an interesting problem earlier today. While running r1soft backup, dmesg was throwing some I/O like the following:
Dec 28 09:28:43 ssd1 kernel: [36701.752626] end_request: I/O error, dev vda, sector 331781632
Dec 28 09:28:43 ssd1 kernel: [36701.755400] end_request: I/O error, dev vda, sector 331781760
Dec 28 09:28:43 ssd1 kernel: [36701.758286] end_request: I/O error, dev vda, sector 331781888
Dec 28 09:28:43 ssd1 kernel: [36701.760992] end_request: I/O error, dev vda, sector 331780864
They didn’t go out after multiple file system checks. That left me no choice other than finding what’s actually in that sector. I could see the sector numbers was increasing by 128 up 10 sequential logs. That makes to understand it could be a specific account causing the errors.
EXT file system comes with an interesting tool called debugfs. This can be used on mounted file system and can be used to track down IO related issues. Although, you require to do some calculation first to convert sector to block number of a specific partition before you can use debugfs.
The lowest sector number in the log was ‘331780864’. First I tracked down the partition where this sector lies. This can be done using fdisk -lu /dev/disk (Make sure to use -u, to ensure fdisk returns the sector numbers instead of cylinder number)
#fdisk -lu /dev/vda
Disk /dev/vda: 1342.2 GB, 1342177280000 bytes
16 heads, 63 sectors/track, 2600634 cylinders, total 2621440000 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0002f013
Device Boot Start End Blocks Id System
/dev/vda1 * 2048 411647 204800 83 Linux
/dev/vda2 411648 205211647 102400000 83 Linux
/dev/vda3 205211648 209307647 2048000 82 Linux swap / Solaris
/dev/vda4 209307648 2621439999 1206066176 83 Linux
Now, find the Start Number < Our Sector number to detect which block contains our desired sector. In our case, it is /dev/vda4. Once done, we need to numeric sector number specifically for this partition, which can be done by subtracting our sector number with start number of the partition. In our case:
331780864 – 209307648 = 122473216
That means, our sector lies in 122473216th sector of /dev/vda4.
Now find the block size by tune2fs:
# tune2fs -l /dev/vda4 | grep Block
Block count: 301516544
Block size: 4096
Blocks per group: 32768
In our case, it is 4096.
Now determine the size of the sectors by bytes. This is shown in fdisk output:
Sector size (logical/physical): 512 bytes / 512 bytes
From the two relations block/bytes and sector/bytes, find sector/block : 512 / 4096 = .125
Now, calculate the block number of 122473216th sector: 122473216 x .125 = 15309152
We can now use debugfs to determine what file we have on that block number as following:
debugfs /dev/vda4
On the debug prompt, type:
debugfs: icheck 15309152
Block Inode number
15309152 2611435
This will show the inode number of the desired file. Use the inode number to run:
debugfs: ncheck 15309152
Inode Pathname
15309152 /lost+found/#29938847
This will show you the desired file that is actually causing the issue. In my case, I could find files that were corrupted in some old fsck, were stored in lost+found and they were missing magic number/incomplete files. Once I had deleted all the files from lost+found, my issue was resolved. Viola!