Mysql has a pretty cool feature with \G, that sets the mysql query result in vertical mode. If you have a table with a lot of column, you will face difficulty to display them in horizontal mode. Hence, you want to see the result vertically.
For Postgres, this is called ‘expanded display’. To set the expanded display on or off, you need to use the following command in psql console:
my_prod=# \x
Expanded display is on.
my_prod=# \x
Expanded display is off.
my_prod=#
If your expanded display is on, then \x will set this to off, else it would set the display to on. If you set the expanded display to on, this would show the column and value in a vertical key value pair style display, which is much easier to understand.
Let’s say, you are architecting a scalable software. Obviously, you would utilize some kind of persistent data storage for your production. If you are developing some kind of transactional software like an ERP/Ecommerce, you are probably more focused into a relational database software like MySQL or MSSQL or PostgreSQL.
Now, one common difficulty for every software architect while working with relational databases, is the ‘Object Relational Impedance Mismatch’ problem. The idea is very straightforward. You design and model your software or programming concept based on Objects, while you store your data in relational tables. Now, how do you map them? As these are different data structures, mapping and utilizing them, is a programming difficulty here.
What is ORM?
In the software world, ORM (Object Relational Mapper) is a form of tool, that exist to resolve the problem. It basically is mapping your relational data into object. That allows you to think your software and data both are stored and operated in Objects. As data is not really stored in an Object, hence, ORM creates an abstraction layer to realize the difference to your software. Using ORM for software design is very useful from architectural point of view, because it takes and returns the same kind of data structure, that you use to design/model your software. It becomes easy to perceive the architecture.
How does DBAL fits here?
As ORM creates an abstraction layer for it’s purpose, it can also be called ‘Database Abstraction Layer’. This is merely conceptual. Now, one purpose of DBAL over ORM, is that DBAL creates the abstraction to keep your software independent from database software alone (Most ORM does the same or helps to achieve the same). So, if you use any of MySQL / MSSQL / Oracle SQL / PostgreSQL or any other SQL based DB engine, it will operate on the same syntax and keep your software compatible out of the box.
So, it’s great, then what’s the problem?
It is obviously conceptually great. But there are cases, when it is better not to use ORM/DBAL. One of the architectural sense of creating abstraction layer in software engineering is that, it creates imperative codes for your mapping. Now, what’s the problem with Imperative codes? If you are unware, Imperative programming refers to the style of programming where we are mainly focused on ‘HOW’ to do something. SQL or relational databases are essentially declarative style of programming, who are focused on ‘WHAT’ to do. For example, when we say ‘select * from users’, it directly gives you the data exists in the users table. We do not care about how does it do it, we only care about the results.
There obviously a catch of declarative code is that, it also creates some kind of abstraction, which uses imperative approach, but it’s underline. For example a Loop in Imperative C is obviously much faster than a loop in Imperative Python (Note: Python can be used in declarative way). But if your software’s imperative code is converting a declarative approach to an imperative piece, then sadly it’s going to be slow, sluggish and less able to scale. ORM or DBAL unfortunately suffers the same. ORM creates an abstraction layer or a slow imperative layer to run declarative SQL. Other cons on using ORM is that, it can duplicate or hobble database structure on your business logic as you are no longer thinking declarative, rather imperative while using ORM.
So where does REST fits in?
To have quicker, simpler and futuristic development, no developer is going to plugin RAW SQL codes in their software. An alternative is to use a declarative REST based api, that uses declarative approach for your database with minimal imperative codes. You can run and consume them as a service with the database software alone. Functional programming is closely related to declarative programming, hence for maximizing performance, you might want to choose a REST api tool that is written in some kind of functional programming language or done in a functional way like with Haskell.
Many database software already started giving HTTP as service protocol with the database software alone, that works in declarative approaches. MySQL comes with a MySQL Router API. PostgreSQL has a solid pREST written in Haskell available in Github. As C# can be written in declarative approach same like Python, there are numerous declarative REST tools written in C# for MSSQL/SQL.
Conclusion
Consuming Declarative API is more like a frontend topic these days since Javascript is taking more functional and declarative futures. React wants you to write codes in declarative approaches, and provides more tools in coming releases with declarative helpers. It is still an odd idea to utilize declarative programming to solve a long existing problem with Object Relational Impedance Mismatch. But then, in the era of millions of users, a declarative database access tool, can cut down a huge amount of cost for infrastructure.
For example, you manage a high traffic website, that utilizes an abstraction layer like an ORM to manage MySQL queries. Now, as a DevOps/System Admin, it becomes difficult for you to get a stat of which MySQL query being overused in the scenario. For these cases, one way, you may get some idea on what being overused, is called ‘MySQL General Logs’. Remember, it is very much different than the MySQL Slow Query Logging. It is not essential to have a slow query in the system to determine if your mysql is boggling. It is very much possible, there are queries, that take very small amount of time, but starves your CPU by executing many times and performs the same operation. Once you are able to identify them, you may utilize any Hashmap based caching strategy like Memcache or Redis or Simple file cache to reduce your load down on MySQL instance or cluster.
First, we create a query logging file and set the right permission:
Once the file creation is done, now we can enable general log either by using mysql shell, if you would like to avoid restarting your mysql instance or in my.cnf file to keep the change permanent. A point to note, you should not do query logging all the time, as it decreases MySQL performance by 15-25%, which might hurt your overall production performance, plus the size of log will cumulatively increase if you have a server that performs over a thousand or more queries per second.
# Type in your shell prompt
mysql
# this will open your mysql shell, you may run mysql commands as below:
mysql > SET global general_log = 1;
mysql > SET global log_output = '/var/log/mysql_query.log';
This should immediately advise mysql to push the logs to /var/log/mysql_query.log.
Now, if you observe the file, you may see the queries are coming up so quickly that you may hardly find anything out from it. The file has no output until you aggregate the result. If you have a large file, a better way to aggregate result by using Lotstash and Elasticsearch. We won’t do that here, that would be a topic for another blog post. We would instead use, some basic shell aggregation to see if we can determine anything useful from this. You may use the following tool, that list the last 10000 lines, then sort, and group the unique lines with the count and order by ascending to put the most frequent query at the end of the line:
This will help you by giving the top most used query in last 10K queries. If the number is more than 5%, you need to pay attention to that. If it is the same query, that means, you may use a Hashmap based caching technique to reduce database boggling and improve performance.
If you are trying to purchase Managed Redis Database, from companies like digitalocean, then, you would get access to those Redis servers, only over TLS/SSL support. Unfortunately, by default redis-cli does not ship with TLS support, hence, you need to either use Tunnel to access redis instance through redis-cli or use different tool for your purpose.
Access Your Redis Instance using Python
If you are developing your application using python, and using a managed redis database, then, you would have to make the redis connection over TLS/SSL. This can be done by setting the ‘SSL’ to True, in the Redis constructor. Here is an example:
import redis
r = redis.Redis(host='db-redis-sfo2-89862-do-user-4233327-0.b.db.ondigitalocean.com', port=25061, password='abcdhjnmjtxeupp', decode_responses=True, ssl=True)
As you can see, I have set the ssl to True at the end, to set the connection over TLS/SSL.
Access Your Redis from Command Line using Redli
If you want to have access to your redis instance through a command line tool, then using redli is my first line choice. Configuring stunnel with redis-cli is also possible, but it would be another topic of discussion here.
Let’s see, how can we install redli:
Redli is a tool developed by IBM with TLS/SSL support. It is written in Golang. You may download a version for Linux from the IBMCloud Github repo and start using it:
This would be a simple step by step post for the help of my customers. You require two tools for this.
i) putty – ssh client ii) WinSCP – File transfer client over SSH (You may use FTP or File manager as well)
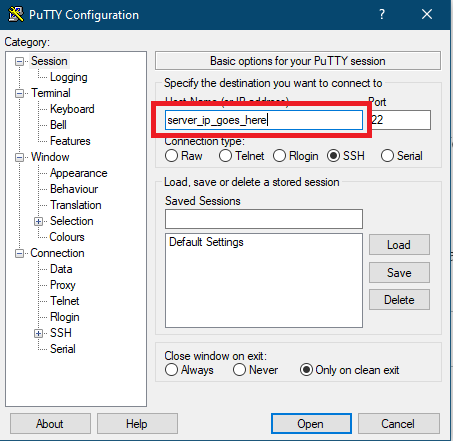
Once you download putty, open it, and use your server’s IP in the Host Name section:
Now, click on open. In the prompt, type ‘root’ as login as and enter. Then type the password and enter. If the password for the root is right, it will login to the command shell prompt or else it will put you in the authentication error console.
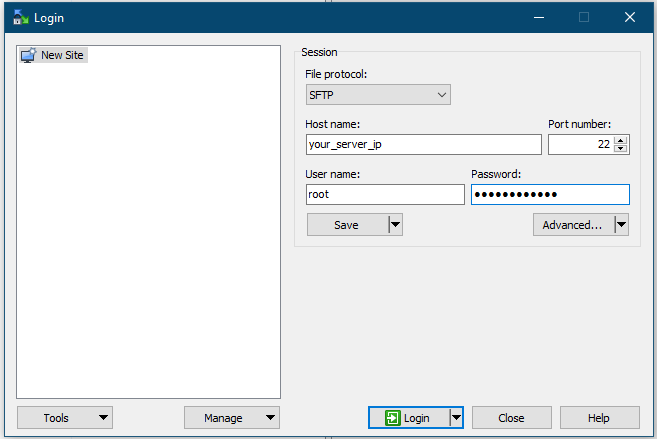
Now, open WinSCP to login to your server using the same manner of SSH. Once done, transfer your sql file to the home directory of root.
Login to your server using WinSCPWinSCP Transfer
To transfer the file, navigate the sql file from your desktop on the left side and then drag it to the right side of WinSCP window. That will start the transfer. Remember the path of the destination on the server. Path is shown in the red marked area in the image.
Once the file is transferred, come back to putty, and change directory to the path you had noted in WinSCP, in our case, it is /root/
cd /root/
mysql -uusername -ppassword your_database_name < your_sql_file_name.sql
Remember the following. Your mysql username should go right after ‘-u’ without any space and the mysql password should be the same without space. Replace the ‘your_database_name’ with your original database name in the server and ‘your_sql_file_name.sql’ with the exact sql file name that you had uploaded.
Now if you allow sometime, the command should complete after the restore. If it returns any error, you would need to attend them to do a complete restore.
Suppose, you have a live Ecommerce system. What you want to see, is how well your revenue is performing comparing to yesterday. But if you are comparing with the total revenue of yesterday, then this won’t be an efficient metric until you reach the end of the day. In real scenario, what you would like, is to compare it with the identical time it is happening right now. For example, if it is 7.19 PM now, then you want to compare either of the following two and show the trend:
i) Revenues within 00:00 – 7:00 PM yesterday to revenues within 00:00 – 7:00 PM today or ii) Revenues within 00:00 – 8:00 PM yesterday to revenues within 00:00 – 8:00 PM today (remember, it is 7.19 PM, so the counter and comparison will continue to flow when you get new order on this case)
Both of the way of seeing trend is useful, depends on your choice, but if you are comparing the metrics with the full of yesterday and the half way through to today, this might not be as useful.
How To Do This In Meatabase?
Please remember, I would be doing this in Metabase. Metabase is an open source data analytical and visualization tool written in Java. It is simple, fast and efficient tool for all square use cases in data analytics. I am using a ‘Reformatted’ real time MySQL database as the data source, hence the query can be used in plain MySQL databases to see results.
Note: We can’t do this with the simple query of Metabase, hence, we have to use the Native query support of Metabase. If your Administrator has limited your access to Metabase to Simple & Custom query, then you can not do this until your Administrator allows you so.
Building The Query
Let’s assume, our orders lie in ‘orders’ table, order creation dates are given in ‘date_created’ column, along with order status and the total value of the order is stored separately under status and total column.
First, we write the sum of the total column with the mysql aggregation function ‘sum’ and set a variable ‘date_created’ based the on the date_created column of orders table as following:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
Now, if you want to use the ‘Trend’ in Metabase, then the query must have ‘Group By’ a timeseries based on which it shows the ‘Trend’ metrics. And we know, that our group by timeseries going to be ‘date_created’. We also know that our conditions of selecting the rows, going to be under the ‘WHERE’ statement, so we will keep it as blank for now. So the query, goes as following now:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
WHERE (
# Our conditions will follow here
)
GROUP BY date(`orders`.`date_created`)
ORDER BY date(`orders`.`date_created`) ASC
We are done with the basic. Now, let’s fill up the WHERE statement. First, you may want to filter out certain ‘status’ of the orders in case you have many. You first, fill that up as following:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
WHERE (
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing')
)
)
GROUP BY date(`orders`.`date_created`)
ORDER BY date(`orders`.`date_created`) ASC
In my case, we are filtering if the order status is either completed, confirmed or processing. We are discarding other statuses like on-hold, or pending or abandoned cart.
Now, let’s think for a moment. We have to compare two time series, that means, we have to first, create an identical time differences. Let me give an example for better understanding. If we are trying to find out, the revenues between 00:00 – 20:00 yesterday and 00:00 – 20:00 today, then we need to have two conditions in WHERE statement for each of them, and they should select all the rows from both conditions, which necessarily means, it would be a ‘OR’ statement. For both cases, we need to select the order statuses, that would necessarily mean something like the following:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
WHERE (
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing')
)
Or
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing')
)
)
GROUP BY date(`orders`.`date_created`)
ORDER BY date(`orders`.`date_created`) ASC
Does the above make sense? If not, soon enough it would be, let’s move on to the next step. Now, how can you align the time to match the hour we have now in SQL query? MySQL curdate() returns the current date, which is today at 00:00 So, if I know the difference of hours left for today, and subtract that from curdate(), that would give us the hour it is now with the date of yesterday. Here is the example:
This is 20th hour, so if we subtract 20 from 24, it would be 4. Now, we subtract 4 from curdate():
10-6-2020 00:00 - 4 Hour 09-6-2020 20:00 which basically is the same hour we are on, of today 10-6-2020 20:00 hour. Simple, isn’t it?
Now, how to write this in SQL query? Let’s see
First, we get 09-6-2020 00:00 Hour, this can be done as following in MySQL with negative Interval of 1 Day from current date.
date_add(curdate(), INTERVAL -1 DAY)
Next, we get 09-6-2020 20:00 Hour using the following:
date_add(curdate(), INTERVAL -(24 - hour(now())) HOUR)
See, how I am calculating the Interval Hour, I am using the MySQL function 'hour()' on another function 'now()' to get the hour we are on, which is giving me 20, then we are subtracting from 24 as 24 hours a day, the result is giving me 4 here. So the output going to be 20:00 hour.
Now, for today, we first need 10-6-2020 00:00 Hour, which is simply:
curdate()
then, the target time is basically the now() function:
now()
We now have all 4 parts of it, here is the completed statement going to be only for the time selections:
For Yesterday:
str_to_date(date_format(`orders`.`date_created`, '%Y-%m-%d %H'), '%Y-%m-%d %H')
BETWEEN str_to_date(date_format(date_add(curdate(), INTERVAL -1 DAY), '%Y-%m-%d %H'), '%Y-%m-%d %H') AND str_to_date(date_format(date_add(curdate(), INTERVAL -(24 - hour(now())) HOUR), '%Y-%m-%d %H'), '%Y-%m-%d %H')
For Today:
str_to_date(date_format(`orders`.`date_created`, '%Y-%m-%d %H'), '%Y-%m-%d %H')
BETWEEN str_to_date(date_format(curdate(), '%Y-%m-%d %H'), '%Y-%m-%d %H') AND str_to_date(date_format(now(), '%Y-%m-%d %H'), '%Y-%m-%d %H')
By adding the above to our basic and simple status selection statements:
SELECT date(`orders`.`date_created`) AS `date_created`, sum(`orders`.`total`) AS `sum`
FROM `orders`
WHERE (
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing' OR `orders`.`status` = 'on-hold')
AND str_to_date(date_format(`orders`.`date_created`, '%Y-%m-%d %H'), '%Y-%m-%d %H')
BETWEEN str_to_date(date_format(date_add(curdate(), INTERVAL -1 DAY), '%Y-%m-%d %H'), '%Y-%m-%d %H') AND str_to_date(date_format(date_add(curdate(), INTERVAL -(24 - hour(now())) HOUR), '%Y-%m-%d %H'), '%Y-%m-%d %H')
OR
(`orders`.`status` = 'completed'
OR `orders`.`status` = 'confirmed' OR `orders`.`status` = 'processing' OR `orders`.`status` = 'on-hold')
AND str_to_date(date_format(`orders`.`date_created`, '%Y-%m-%d %H'), '%Y-%m-%d %H')
BETWEEN str_to_date(date_format(curdate(), '%Y-%m-%d %H'), '%Y-%m-%d %H') AND str_to_date(date_format(now(), '%Y-%m-%d %H'), '%Y-%m-%d %H')
)
GROUP BY date(`orders`.`date_created`)
ORDER BY date(`orders`.`date_created`) ASC
Simple, huh? Indeed, it is. If you run this query in phpmyadmin, or your mysql console, you will see the revenue amounts from the yesterday till the hour we are running through at this moment of today. But in Metabase, you can get a beautiful ‘Trend’ number metric with it. Just go To Visualization >> Trends to show you the Trend Number Metric for this as following:
It is cool to see how good or bad you are doing by this hour than yesterday.
Well, this is an interesting topic. Earlier today, I answered the same question in a Elasticsearch Community Group in Facebook, thought to keep this documented as well.
Primarily, if you are aware of how Elasticsearch is storing data (The document like), you might think, it is a full fledged NoSQL database, but you need to know, it is not. If you have looked at several NoSQL databases, you might already be thinking, there is probably no standard definition of NoSQL databases, which is partially true, again, there still is definition of database management systems, where it doesn’t fit. Does that mean, we can’t use ES as the primary data store? No, that’s doesn’t mean that. You certainly can, but there are use cases. Let’s look at couple of points before we conclude.
Database Transactions
ES has no transaction. Even the algorithm that ES implements, Lucene Search, which has transaction in the original design, but ES doesn’t have any transaction. When there is no transaction, the first thing you need to remember, it has no rollback facility. That also means, every operation is atomic by design, and there is no way to cancel, abort or revert them. This also means, you have no locking standard in the system. If you are doing parallel writes, you need to be very careful about the writes here because ES is not giving you any guarantee to parallel writes.
ES Caching Strategy
Elasticsearch is a ‘near real’ time search engine. It is not a ‘real’ time search engine. It has a caching standard, that refreshes every 1 second. This is ‘by design’ of Elasticsearch. So, what’s the problem with it? The problem is, you may get tricked by the ES cache if you are immediately asking for a read for a quick write operation and it is within 1 second. But as most of the cases, ES is not written much often (Since most of the people do not use it as primary storage), most of the people thinks it is real time. But it is not. It’s cache can trick you in intense cases, where writes won’t be immediately available to you for read.
User Management
ES user management is no where near to a full fledged DBMS, only because ES doesn’t need to. They have never announced themselves as a NoSQL DBMS, hence they do not require to add the functionality in full square. They only implements the facilities that ES Ecosystems require.
So … ?
So, what does all these mean to you? If you have an extremely large read featured application, where updates are very rarely or occassionaly done, then you can definitely go with ES as your primary document storage engine. But if you have a write oriented application, requires complex user management or parallel threads require write access, then you better be choosing a standard DBMS for your business and use ES as secondary data store for your analytics and searches.